6. Program Representation and Interpretation
In this chapter, we discuss how we can represent and ultimately execute or interpret programs in a particular language. To this end, we need to talk about the toolchain required to do so, as well as techniques for defining the meaning (semantics) of programs in our language.
6.1. Programming language toolchains
We will start with an overview of the phases of programming language compilation/interpretation toolchain:
source code (string stored in file)
lexical analysis
sequence of tokens
syntax analysis (parsing)
abstract syntax tree <- interface between front end and back end
static checks
optimization
transformed abstract syntax tree
code generation
machine code or byte code
execution on physical hardware, virtual hardware, or virtual machine
alternative: direct interpretation of abstract syntax trees
Reference: Mogensen
6.1.1. Cross-compilation
Cross-compilation is a useful technique when the target environment does not provide sufficient computational resources to compile software in the target environment itself. Common examples include mobile phones and other embedded devices. For example, one usually develops Android apps on a development machine, tests them on an Android virtual device (emulator), and deploys them to an actual phone or tablet.
The following example shows cross-compilation of a small C program on a development machine and execution in the target environment.
First, we compile the source on our development machine, in this case, a hosted Linux VM using the OpenWrt embedded Linux toolchain:
[laufer@boole:~/Work/hello] 130 $ cat hello.c main() { puts("hello ETL!"); } [laufer@boole:~/Work/hello] $ ~/Work/OpenWrt-SDK-15.05.1-ramips-rt305x_gcc-4.8-linaro_uClibc-0.9.33.2.Linux-x86_64/staging_dir/toolchain-mipsel_24kec+dsp_gcc-4.8-linaro_uClibc-0.9.33.2/bin/mipsel-openwrt-linux-uclibc-gcc hello.cNow we deploy the resulting executable to the target environment using, say,
scp.Finally, we run this executable natively on a MIPS-based embedded Linux device sold as a “portable travel router”:
root@ExPodNano:~# ldd ./a.out libgcc_s.so.1 => /lib/libgcc_s.so.1 (0x770d5000) libc.so.0 => /lib/libc.so.0 (0x77069000) ld-uClibc.so.0 => /lib/ld-uClibc.so.0 (0x770f9000) root@ExPodNano:~# ./a.out hello ETL!
6.2. Compiler front-end concepts and techniques
In this section, we will discuss the key front-end stages, lexical analysis and syntax analysis, and related concepts and techniques.
6.2.1. Lexical analysis
regular expressions, NFA, DFA (Mogensen ch. 2)
6.2.2. Syntax analysis
context-free grammars, EBNF, parsing (Mogensen ch. 3)
6.2.3. Alternative front-end approaches
Scala parser combinators
Parboiled 2 PEG library
6.3. Programming language semantics
Semantics, a formalization of the meaning of programs in a particular language, includes static and dynamic semantics.
static semantics (compile-time)
flow analysis
typing
dynamic semantics (run-time)
denotational
operational, e.g. our interpreters
axiomatic
The Interpreter pattern is related to the discussion of dynamic semantics.
6.4. Case study: a simple imperative language
In this section, we discuss the design of an interpreter and programming environment for a simple imperative language.
The accompanying lecture is available as a set of screencasts:
6.4.1. Objectives
We are leading toward building an interpreter for a language resembling JavaScript with object-like features. We are doing this with two aims in mind:
To understand an object-oriented programming language from the “inside”.
To understand better the object-oriented and functional design patterns that we have learned by using them in the context of a small but somewhat sophisticated program.
6.4.2. Syntax
Our language has the following features:
Integer expressions given by the BNF grammar:
e ::= variable
| const
| e1 + e2
| e1 - e2
Statements given by the BNF grammar:
S ::= x = e
| S1 ; S2
| while (e) S
In the context of the lectures so far, we have made the following changes. We have added variables to expressions, thus we can handle cases like x + 3, whereas earlier we could only write expressions such as 4 + 3. We have also introduced the assignment statement as a way to change the contents of a variable. In addition, we allow statements to be put in sequence. We also permit simple while expressions, where the guard is an expression and the loop body is executed while the gurad expression evaluates to a non-zero integer value.
6.4.3. Structured operational semantics (SOS)
We first formalize the intuitive execution semantics of the toy language. The point of doing this is to present the basic ideas in the interpreter without getting tied up in the programming details of the interpreter. In any case, these details are presented later in this lecture. Since our toy language has variables, we need to keep track of the state of variables. We view variables as objects with two capabilities:
v.get() returns the current value of the variable
v.set(int i) changes the current value of the variable to that of i
We think of the state of the program (memory store), which we write M, as a map that associates identifiers with variable objects.
The rules for evaluating expressions are quite simple.
Evaluating constant c. Every constant evaluates to itself.
Evaluating a variable whose name is x: Retrieve the variable object (say v) associated with x from the memory store M, by using M(x). The required result is computed by invoking v.get().
Evaluating e1 + e2: Evaluate e1 first, say to yield value r1. Evaluate e2 next, say to yield value r2. The required result is the numeric value r1 + r2.
Evaluating e1 - e2: Evaluate e1 first, say to yield value r1. Evaluate e2 next, say to yield value r2. The required result is the numeric value r1 - r2.
The evaluation rules are written out precisely in the following picture.

The rules for executing statements is as follows. In contrast to expression evaluation, statement execution does not yield a result. The primary consequence of executing a statement is the side effect on the store, ie. changes in the values of variables.
Executing an assignment statement: Consider the assignment statement x = e. Here e is an expression. The steps are as follows: First, evaluate the expression e to yield a result, say r. Next, retrieve the variable object (say v) associated with x from the memory store M, by using M(x). Perform v.set(r) to change the value of the variable object.
Executing a sequence of statements S1; S2: Execute S1 first. When that terminates, execute S2.
Executing while (e) do S: Evaluate the condition e to yield a result r. If r is zero, the execution terminates. Otherwise, execute S and repeat the process.
The execution rules are given in the following pictures:


Note that the connection between the various statements is that they share a single store, ie. in the sequence of statements x = 2; y = x + 1, the second reference to x reflects the effect of the first assignment because of the (shared) store between the two assignment statements.
6.4.4. The interpreter program
We now go ahead and write the interpreter program. The entire code is available as part of the misc-scala example. A similar example but based on F-algebras and with better runtime error handling is also available: simpleimperative-algebraic-scala.
6.5. Case study: a simple imperative language with records
In this section, we discuss the design of an interpreter and programming environment for a simple imperative language with records (like classes with public fields and without methods).
6.5.1. Objectives
We are leading toward building an interpreter for a language resembling JavaScript with object-like features. We are doing this with two aims in mind:
To understand an object-oriented programming language from the “inside”.
To understand better the object-oriented and functional design patterns that we have learned by using them in the context of a small but somewhat sophisticated program.
We now consider the changes that arise from the addition of records. Thus, we permit:
declaration of record types
creation of new records of a given record type
selection of record fields
use of records on the left and right hand side of expressions
6.5.2. Syntax
Our language has the following features:
The syntactic feautures of our language are captured by the following grammar. For motivation, the sort of program that we are interested is exemplified by:
StudentCourseRecord = record
int firstExamScore;
int secondExamScore;
int totalScore;
end;
StudentSemRecord = record
StudentCourseRecord course1;
StudentCourseRecord course2;
end;
StudentSemRecord r = new StudentSemRecord();
r.course1 = new StudentCourseRecord();
r.course1.firstExamScore = 25;
r.course1.secondExamScore = 35;
r.course1.totalScore = r.course1.firstExamScore + r.course1.secondExamScore;
r.course2 = r.course1;
In the C language, such things are known as structs. In familiar object-oriented terminology, we can think about them in this way:
record types are classes whose only members are public member variables
records are objects
fields are public member variables
The record type definitions in the previous example would look as follows in Java, and the rest of program would look the same:
class StudentCourseRecord {
public int firstExamScore;
public int secondExamScore;
public int totalScore;
}
class StudentSemRecord {
public StudentCourseRecord course1;
public StudentCourseRecord course2;
}
Formally, we proceed via the following BNF grammars. To simplify life for us, we will ignore type information. In this BNF grammar, we are a little bit more careful to separate L(eft) values and R(ight) values. L-values are those that can appear on the left hand side of an assignment statement, and R-values are those that appear on the right hand side of an assignment.
Record definitions are given by the BNF grammar:
Defn ::= record
FieldList
end
FieldList ::= fieldName, FieldList
| fieldName
L-values (fields selected from records, as well as variables) are given by the BNF grammar:
Lval ::= e.fieldName
| variable
Expressions (R-values) are given by the BNF grammar:
e ::= new C
| Lval
| const
| e1 + e2
| e1 - e2
Statements are given by the BNF grammar:
S ::= Lval = e
| S1; S2
| while (e) do S
We first formalize the intutive execution semantics of the toy language. As before, the point of doing this is to present the basic ideas in the interpreter without getting tied up in the programming details of the interpreter. In any case, these details are presented later in this lecture. In particular, in this initial first cut, we will begin by ignoring declarations. Also, in this new presentation
Recall that we viewed variables as objects with two capabilities:
get() returns the current value of the variable
set(int x) changes the current value of the variable to that of x
Records are thought of in a similar light.

As before, we think of the state of the program, which we write S, as a map that associates identifiers with variable objects. Furthermore, as before, we distinguish evaluation and execution. In evaluation, there are two subcases, evaluating to an L-value and evaluating to an R-value.

There are two ways of having L-values. One is via variables and the second is via field selection.
The L-value associated with a variable name is the associated variable object.
The L-value associated with a selection e.f is obtained by first evaluating the expression e to an R-value, say r. Next, lookup on the record r with field name f is used to get the desired L-value.
These evaluation rules are written out precisely in the following picture.

Our earlier rules for evaluating R-values are presented again below..
Evaluating an L-value. In our setup, every L-value (say l) is a variable object that is obtained from the store M. Execute l.get() to compute the return value. This rule subsumes the earlier case for variables.
Evaluating e1 + e2: Evaluate e1 first, say to yield value v1. Evaluate e2 next, say to yield value v2. The required result is v1 + v2.
Evaluating e1 - e2: Evaluate e1 first, say to yield value v1. Evaluate e2 next, say to yield value v2. The required result is v1 - v2.
Evaluating constant c. Every constant evaluates to itself.

The rules for executing statements are as follows. They are similar to the ones seen before. The primary consequence of executing a statement still is the side effect on the store, ie. changes in the values of variables.
Executing an assignment statement L = e. Here L is an L-valued expression and e is an R-valued expression. The steps are as follows. First, evaluate the expression L to yield an L-value, say l. Next, evaluate the expression e to yield an R-value, say v. Next, use l.set(v) to change the value of the variable object.
Executing a sequence of statements “S1; S2” and a “while” loop are as before.
The execution rules are given in the following pictures:

6.5.3. Implementation
The entire code for the implementation of the simple imperative language with records is available here.
6.6. Type systems
Type systems are an important aspect of programming languages. We identify the following dimensions in the type system design space:
static versus dynamic typing
strong versus weak type safety
implicit versus explicit type information
nominal versus structural type equivalence
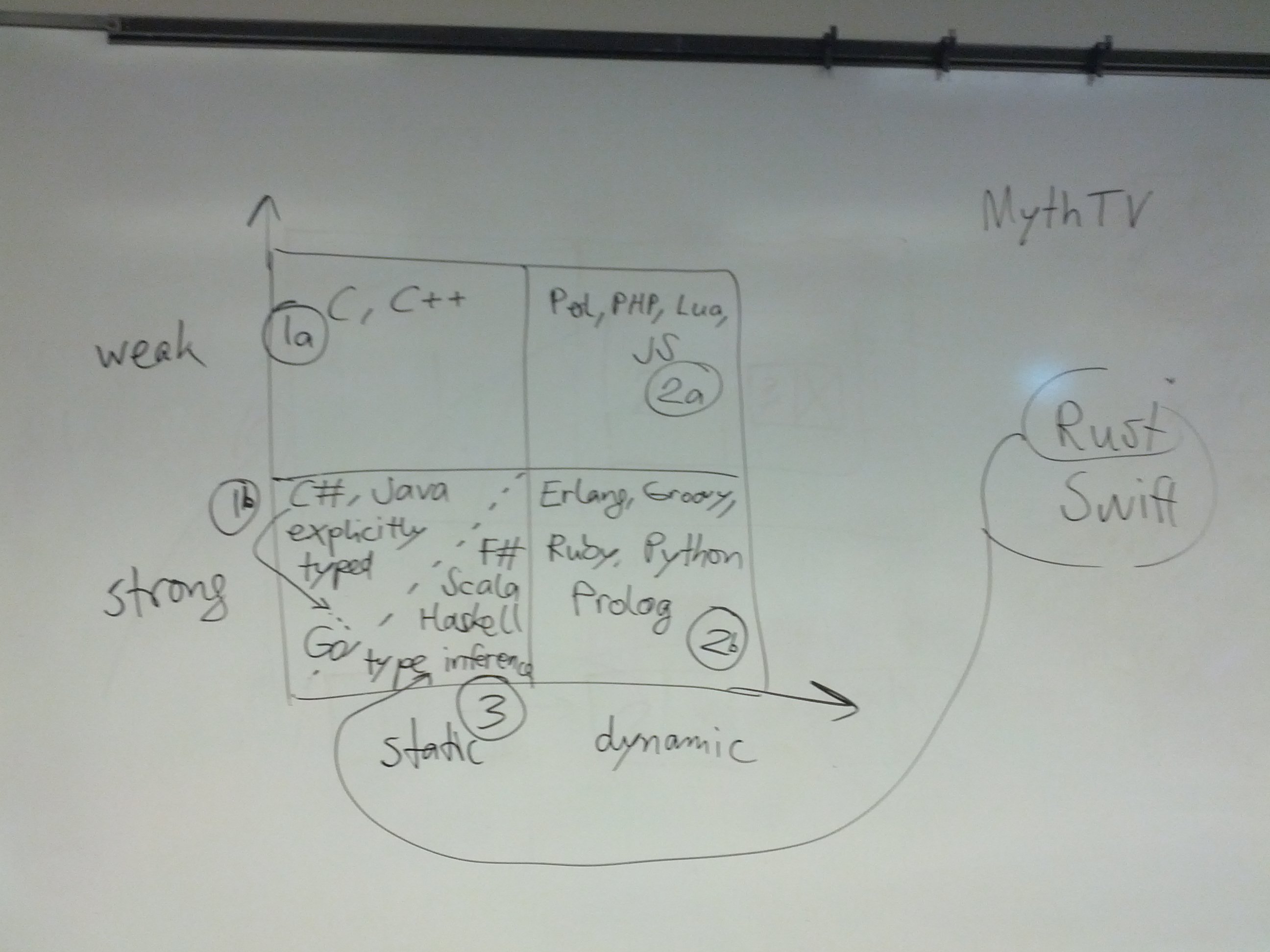
Additional information is available here:
Todo
elaborate on the design space for polymorphism (Cardelli/Wegner)
6.7. Domain-specific languages
Domain-specific languages are special-purpose languages for solving problems in particular domains. We identify the following dimensions:
internal/embedded language versus external language
business domain versus technical domain

In addition, there is a continuum between APIs and internal DSLs.
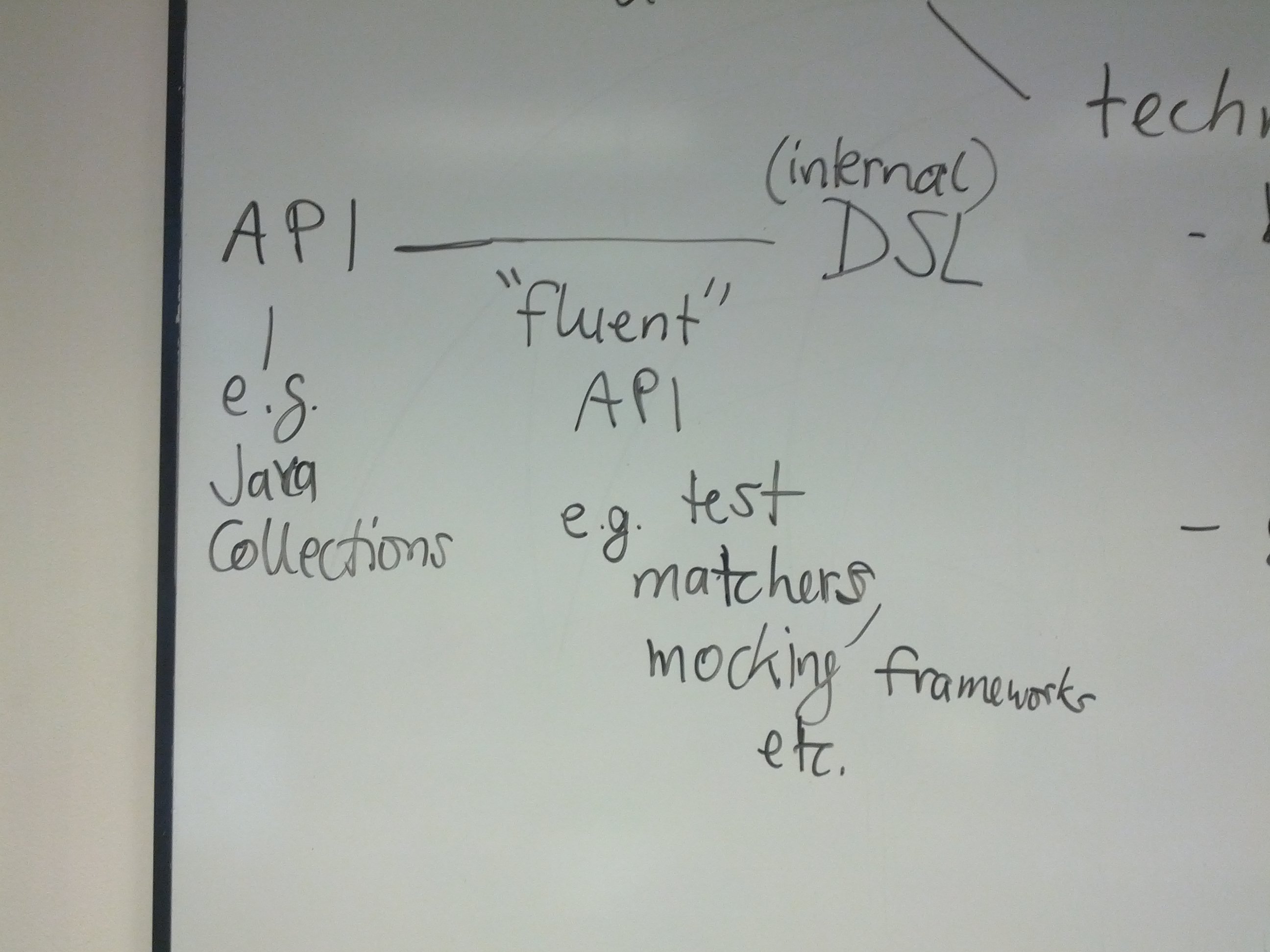
Additional information is available here: